
Développement d’un Moteur de Recherche en Python
Projet de Traitement du Langage Naturel (NLP)
Fonctionnalités Clés
- Vectorisation TF-IDF via
scikit-learnou via une implémentation personnalisée. - Pré-traitement NLP avancé : stop-words (NLTK), et comparaison entre lemmatisation (SpaCy) et stemming.
- Deux modes d’exécution :
query(requêtes manuelles) ettest(évaluation automatique). - Mesure de similarité par similarité cosinus.
- Statistiques : accuracy « Top 1 » (le bon document est en première position) et « Top 5 » (le bon document est parmi les 5 premiers résultats), avec une verbosité réglable (
--verbosity 0|1|2).
Approche Technique Détaillée
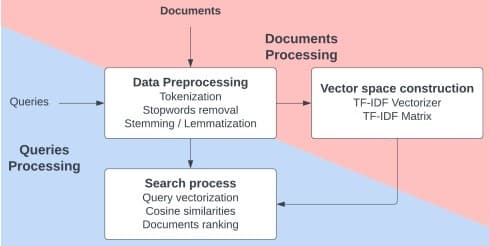
1. Indexation (Phase de "Build")
a) Pré-traitement des documents
- Lowercasing : tout en minuscules.
- Tokenisation via regex
\b\w[\w\-]+\b(gère les mots composés). - Filtrage des Stop-words : Suppression des mots courants (ex: "le", "de") avec NLTK.
- Lemmatisation (
spaCy) ou stemming (SnowballStemmer).
→ spaCy intègre la tokenisation ; le stemming ré-utilise la regex.
Remarque : ⚠️ Certains lemmes (ex. « être », « avoir ») restent hors de la liste stop-words. - Sortie :
• sk-learn → chaîne « bag-of-words »
• custom → liste de tokens (contrôle intégral TF / IDF) - Gain attendu : vocabulaire réduit, matrice moins clairsemée et regroupement morphologique.
b) Construction de la matrice TF-IDF
| Scikit-learn | Custom (TFIDF_Vectorizer) |
|---|---|
Matrice scipy.sparse optimisée | Matrice NumPy dense |
| IDF lissé par défaut | IDF classique : log((N+1)/(df+1)) |
| Production-ready, très rapide | Pédagogique, inspectable, personnalisable |
2. Recherche & Évaluation (Phase de "Run")
a) Pré-traitement d’une requête
Identique aux documents (lowercasing, tokenisation, stop-words, lemmatisation/stemming) pour garantir la cohérence des features.
b) Vectorisation & similarité
vectorizer.transform([tokens]) projette la requête pré-traitée dans l’espace TF-IDF :
- Entrée : liste de tokens (ou bag-of-words)
[w₁, …, wₙ]. - Sortie : vecteur ligne q de dimension 1 × |Vocabulaire| (même dimension que chaque vecteur document).
On calcule ensuite la similarité cosinus entre la requête q et chaque document d :
cos(q, d) = (q · d) / (‖q‖ · ‖d‖)- q : vecteur TF-IDF de la requête (1 × V).
- d : vecteur TF-IDF d’un document (1 × V).
q · d: produit scalaire (similarité brute).‖q‖et‖d‖: normes L2 (mise à l’échelle).
Les scores sont ensuite triés par ordre décroissant pour obtenir le ranking final des documents pertinents.
c) Modes d’exécution
- Mode
query: l’utilisateur tape sa requête et l’article le plus pertinent est affiché. - Mode
test: 100 requêtes sont évaluées automatiquement pour calculer l’accuracy Top 1 / Top 5.
Exemples de requêtes (mode test)
"langue roumain" → wiki_066072.txt
"énergie marine" → wiki_090261.txt
"où est tianjin" → wiki_013117.txtRésultats et Analyse
| Scénario | Accuracy Top 1 | Accuracy Top 5 |
|---|---|---|
| A : Scikit-learn + Lemmatisation | 82% | 97% |
| B : Scikit-learn + Stemming | 85% | 97% |
| C : Custom + Lemmatisation | 81% | 97% |
| D : Custom + Stemming | 85% | 97% |
Tous les scénarios atteignent une accuracy Top 5 de 97%. Les échecs systématiques (ex: "Elizabeth Ière" vs "Élisabeth Ire") sont dus à des différences orthographiques ou sémantiques, montrant les limites d'une approche purement lexicale.
1. Différences Stemming vs. Lemmatisation
Le stemming a amélioré certains cas (ex: "24 heures du Mans"), tandis que la lemmatisation a parfois conservé des stop-words (être, avoir) qui ont nui à la pertinence.
2. Comparaison des Vectoriseurs
Notre implémentation "custom" était transparente mais moins rapide et a échoué sur certaines requêtes où scikit-learn réussissait, suggérant des différences subtiles dans les optimisations d'IDF.
Potentielles Améliorations
- Recherche sémantique (SBERT, word embeddings).
- Détection et correction d’orthographe sur la requête.
- Index inversé persistant (SQLite, Whoosh, FAISS).
- Tokenisation par sous-mot pour mieux gérer les variantes lexicales.
Extrait de la Boucle Principale
# search_engine.py
if __name__ == "__main__":
args = parser.parse_args()
engine = SearchEngine(...)
engine.create_vector_space()
if args.mode == "query":
while True:
query = input("Tapez votre requête > ")
# ...
engine.search(query)
else:
engine.test_queries()Le code complet, incluant l'implémentation du vectoriseur TF-IDF custom, est disponible sur GitHub.
Voir le projet sur GitHub